
You must log in or register to comment.
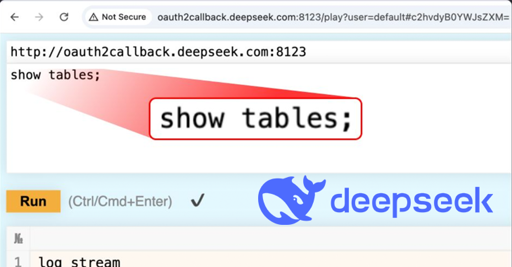
AI is clearly no match for little Bobby Tables.
the boy is all grown up
Did OpenAI and Microsoft ask for my permission? I don’t think so
both OpenAI and Microsoft are probing whether DeepSeek used OpenAI’s application programming interface (API) without permission to train its own models on the output of OpenAI’s systems, an approach referred to as distillation.
That would definitely show up in the quality of responses. Surely they have better and cheaper training sources…
And if they did… So what
Get fucked corpo parasite. Nobody fucking care about another corpo punking u esp when it is done in spectacular manner.
I think it’s reasonably likely. There was a research paper about how to do basically that a couple years ago. If you need a basic LLM trained on a specialized form of input and output, getting the expensive existing LLMs to generate that text for you is pretty efficient/inexpensive, so it’s a reasonable way to get a baseline model. Then you can add stuff like chain of reasoning and mixture of experts to improve the performance back up to where you need it. It’s not going to be a way to push the state of the art forward, but it’s sure a cheap way to catch up to models that have done that pushing.
LOL, their code is probably written by AI.
Considering that they actively recruit young and inexperienced people to work for 'm, there’s a big chance, yeah.
After removing ChatGPT, anti-libre software, my data never leaves my control.
only if it would be so easy. think about your data that’s taken about you and you can’t refuse. healthcare, home ownership, if you’re still learning then a bunch of data about your progress, and maybe even your handwriting
Where’s your solution?
Unfortunately I don’t have one, other than a long term plan of eating the rich. But the issue is there and we shouldn’t ignore it.
only solution to not having data harvested is to not have even been born. YW
Lemmy.world admins have your data right here, what are you on about?
Tell us, how many of my posts here are not public?
I smell politics here over ethical hacking
Normally, when vulnerabilities are found, the responsible steps are to disclose to the site owner first before waiting for them to resolve it (ie 90 days).
I didn’t see that mentioned in Wiz’s article - which is showing their data & links to the vulnerabilities.
Exposing your database directly to the internet? God damn, it really is amateur hour.
True, but they’re all as bad as each other. OpenAI was breached last year too…
That was quick


